

 Magyar
Magyar0. A nyelvi adatok térbeli leképezésének immár több évszázados hagyománya van a nyelvészetben. Ennek hozadékai alig kaptak helyet a közoktatásban, hiszen azokat jórészt a felsőoktatás egyes nyelvészeti kurzusai kamatoztatják. Ha az utca emberét kérdeznénk arról, mi jut eszébe a névföldrajz kapcsán, bizonyára sokakban felidéződnének azok az ábrák, amelyek a magyar nyelvjárások területi elrendeződését kartografikusan igyekeznek bemutatni. Másodjára bizonyára a szókészletbeli és hangtani eltérések iskolapéldáit sorolnák. Talán a szakemberek közül is csak kevesen gondolnának arra, hogy a jelenkori és a történeti családneveink is sajátos táji elrendeződést mutatnak. Gyanítom, az egyetemi katedrán állva is csak kevesen nyúlnának a családnévállomány kínálta hangtani, morfológiai, lexikológiai példákhoz, amikor a nyelv területi változatairól kívánnak szólni. Ha ez utóbbi távolságtartásnak az okait boncolgatnánk, hamar eljutnánk a felismerésig: dialektológusok jó néhány nemzedéke nőtt fel úgy a szakmában, hogy a magyar nyelv táji változatainak vizsgálatakor figyelmen kívül hagyott egy nagyon fontos szeletet – a családnevek téri tagolódását. Azt gondolom, ebben az ügyben az utóbbi évtizedben sem történt lényeges változás. Ezt az űrt kívánják betölteni azok a kezdeményezések, amelyek az ezredforduló utáni évtized végén kezdtek intenzíven foglalkozni a témával. Noha magam is több monografikus munkában, illetőleg jó néhány tanulmányban közzétettem az eredményeket, ezek a szakmában jórészt visszhangtalanok maradtak. Habár a családnévföldrajz által számos, mind ez ideig rejtett történeti, művelődés-, népiség- és nyelvtörténeti stb. összefüggésre sikerült magyarázatot találni, az eredmények ízlelgetésnél a névtudomány berkeiben sem sikerült messzebbre jutni a szakembereknek. A rokon diszciplínák képviselői pedig mind ez ideig semmiféle érdeklődést sem mutattak a téma iránt. Éppen ezért örültem annak, hogy helyet kaptam a mostani tematikus számban, ahol egyebeken túl néhány példa segítségével felvillanthatom, milyen gazdag nyelvészeti és extralingvális szempontrendszer szerint lehet vallatóra fogni a családneves adatbázisokat.
Kellő tér hiányában e helyütt nem kívánok szólni a névföldrajzi előzményekről, mint ahogy a családnévatlasz eddigi munkálatai ügyében is a korábbi közleményekre kell hagyatkoznom. E helyütt csupán a készülő magyar családnévatlasszal kapcsolatos leglényegesebb információk felvillantására szorítkozom.
Két időszelet korpuszára támaszkodhatunk. Az egyik a 18. század elejéről származik, amely az 1720-as országos összeírás anyagának sajátos, általam strukturált és előkódolt adatbázisa. Az adatbázis-építés és előkódolás során figyelni kellett arra, hogy speciális kereséseket is lehessen végezni, illetőleg olyan adattáblákat készíthessek, amelyeket a kartografálás során a térinformatikai szoftverek is kezelni tudnak.
Az 1720-as összeírás a korabeli Magyar Királyság területéről mintegy 179 ezer korabeli adóköteles személy család- és keresztnevét tartalmazza, éspedig lokalizálható formában. A keresztnevek latinul (latinosan) lettek feljegyezve, a családnevek azonban abban a formában maradtak az utókorra, ahogy a conscriptorok az adatközlőktől hallhatták őket. Éppen ezért a korpusznak erre a rétegére úgy tekinthetünk, mint valamiféle élőnyelvi gyűjtésre, hiszen számtalan korabeli táji sajátosságot hagytak az utókorra: jelesül hangtani, morfológiai, lexikológiai, szemantikai és morfoszemantikai stb. vizsgálatokhoz nyújtanak kellő alapot. Ha az adatokat térképre vetítjük, akkor általuk nyelvföldrajzi megfigyelésekre nyílik lehetőségünk.
A másik időszelet a 2009-es magyarországi lakónépesség több mint tízmillió alapadatot tartalmazó családnévállományán alapul. Ennek adatai abban a formában állnak rendelkezésre, ahogy a hatóságok a népesség-nyilvántartásban elektronikus adathordozón a 2009. január 1-jei eszmei állapot szerint tárolták őket. Értelemszerűen ezt is strukturáltam és előkódoltam, hogy benne a keresést minél hatékonyabban lehessen elvégezni.
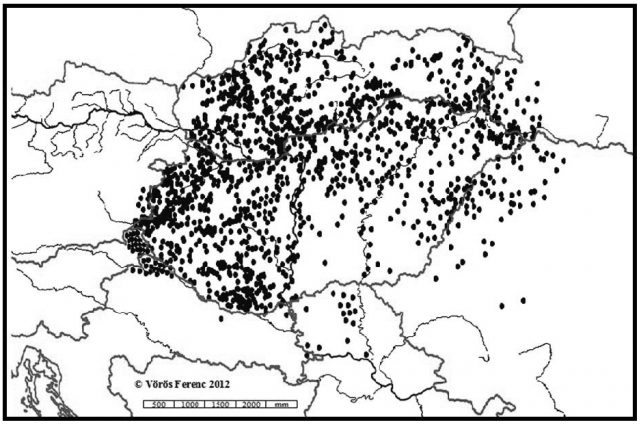
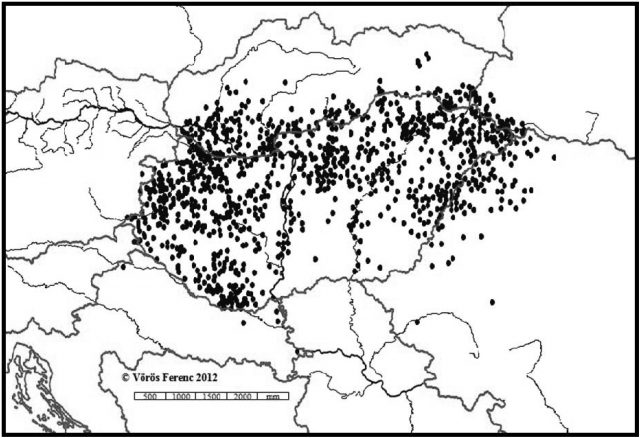
Mindkét fentebb említett adatbázis egyfajta szinkrón metszetnek tekinthető. Közöttük mintegy háromszáz évnyi „szakadék” tátong, ám dacára ennek úgy gondolom, hogy a két metszet összevetése kiváló lehetőséget kínál nemcsak az állapotok, hanem bizonyos, az idők során végbement változások megragadására is. Bizonyára első hallásra furcsán hangzik, hogy mostanáig egyebeken túl gyakorta mégis arra koncentráltam, mi az, ami a magyar(országi) családnévállományban táji szempontból is állandóságot mutat, noha időközben jelentősen felgyorsultak a belső és külső migrációs folyamatok. Ez utóbbi tényezővel kapcsolatban az volt a kiindulási alap, hogy alapvetően a népességmozgások sem képesek teljesen felülírni egyes jelenségek korábbi téri tagolódását, különösen akkor nem, ha nagy tömegű adattal dolgozhatunk. Ez utóbbit azért is kell hangsúlyoznunk, mert a névföldrajzi előzmények egyike sem rendelkezett a fentebb említett adatbázisokhoz hasonló nagyságrendű alapadattal, ráadásul a többségüknek a forrásai csak kisebb területet fedtek le. Azok, amelyek országos hatókörűek voltak, a reprezentativitás elvét hangsúlyozva többnyire a nyelvterület különböző részeiről származó kutatópontokkal dolgoztak. Ennek az állatásnak az igazolására álljon itt Hajdú Mihály kutatópontjainak (Hajdú 1994, 2003) térképe! Hajdúra nem ok nélkül hivatkozom, hiszen őt megelőzően egyetlen szakembernek sem sikerült a nyelvterületnek ekkora részét lefedni. A térképen szereplő lokuszok névállománya a középmagyar kor végétől lényegileg napjainkig teszi lehetővé az egyes jelenségek vizsgálatát és a különféle folyamatok nyomon követését. Megjegyzem, Hajdú korpusza mennyiség tekintetében is minden korábbi kutatást fölülmúl, de meg sem közelíti az 1720-as és 2009-es adatbázis nagyságrendjét.
1. ábra. Hajdú Mihály új- és legújabb magyar kori magyarországi kutatópontjai (18. század; 1772–2003 között)
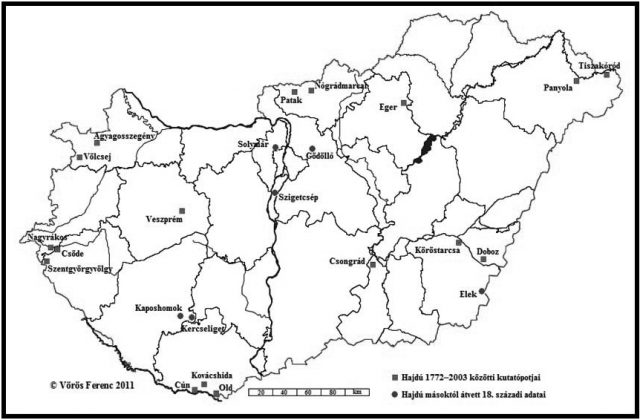
A kartogram alapján egyértelműen megállapítható: a) hatalmas térségek maradnak látókörünkön kívül; b) a kutatópontok jelentős része a nyelvterület pereméhez közel helyezkedik el; c) egyetlen történeti adat sem lépi át a Trianonban meghúzott politikai határokat, kivéve az az öt bukovinai falu – Andrásfalva, Hadikfalva, Istensegíts, Fogadjisten és Józseffalva –, amelyeket az 1. ábra ugyan nem tartalmaz, de amelyekről köztudott, hogy mindig is kívül estek a történelmi Magyarország határain.
1. A tulajdonnevek a nyelvtörténet kutatóinak megkerülhetetlen fogódzókat jelentenek az ómagyar kor egyes időszakai nyelvállapotának és folyamatainak leírásához. Ezzel kapcsolatban érdemes hosszasabban idézni Kázmér Miklóst (Kázmér 1970, 60. p.), aki így fogalmaz: „A magyar nyelvtörténet számára a 11–12., sőt bizonyos mértékig a 13–14. századi tulajdonnevek is nélkülözhetetlenek. Igen jelentős mértékben ezek elemzésével derült fény nyelvünk történeti korszakából három-négy évszázad nyelvi eseményeire. A későbbi korokra, amelyekből szövegek már nagyobb mértékben maradtak fenn, a tulajdonnevek nyelvtörténeti forrásértéke kétségtelenül csökken (névélettani szempontból természetesen változatlan), úgy vélem mégis, hogy ilyen szempontból is érdemes megvallatni a 14. század utáni neveket. Kétségtelen, hogy ez a vizsgálat a múlt nyelvének csak egy kisebb szektorára, elsősorban a hangtanra, szerényebb mértékben az alaktanra és a szótörténetre terjedhet ki, viszont – úgy látszik – ez a forrástípus az említett korlátokon belül olykor talán többet is tud nyújtani a szövegek vallomásánál. Két vonatkozásra gondolok: a nyelvföldrajzra és a kronológiára” (a kiemelések tőlem – V.F.). Tulajdonképpen többek között az ősmagyar kor modellálását is részben ezek a munkálatok teszik lehetővé, éspedig oly módon, hogy a protougor és kora ómagyar kori állapotok közötti időszakot az előzmények és következmények ismeretében rekonstruáljuk. Mivel ennek során a mintegy kétezer évet kitevő köztes állapotra nem állnak rendelkezésünkre nyelvi források, ezért az ősmagyar korra vonatkozó nyelvföldrajzi megállapításokat is kénytelenek vagyunk mellőzni. Igaz, a kora ómagyar korra vonatkozó nyelvföldrajzi megfigyelések is többnyire kellően bizonytalan lábakon állnak, hiszen a rendelkezésünkre álló adatok meglehetősen szórványosak. Felbukkanásuk helye korántsem ad mindig megfelelő alapot a hajdani nyelvváltozatok téri tagozódásának behatárolására, jóllehet az ómagyar korról úgy gondolkodunk, hogy akkor következett be az a váltás, amelynek során a törzsi nyelvjárások egy idő után fokozatosan területi változatokká váltak. Ugyanakkor jószerivel vajmi keveset tudunk az akkortájt kizárólag területi változatokban élő magyar nyelv nyelvjárásainak területi elrendeződéséről. Talán korántsem véletlen, hogy a régebbi és az újabb nyelvtörténeti kézikönyvek az adatok helyhez kötésének kérdésében egyaránt meglehetősen szűkszavúak, holott az egyes jelenségek gócának meghatározása a terjedés irányának és módjának behatárolásában is nagyban segíthetné a nyelvtörténészeket. Igaz, a történeti-földrajzi tényezőket többnyire a nyelvi változások másodlagos okaiként szokás számon tartani, amelyek a tágabban értelmezett társadalomtörténeti kérdésekhez vezetnek el bennünket. A történeti vizsgálatoknak tehát elengedhetetlen része annak megválaszolása, hogy mikor, kik és hol, a nyelvterület mekkora szeletén használták az adott nyelvi elemet vagy jelenséget. A hol kérdésére nyelvföldrajzi vizsgálatok segítségével tudunk megnyugtató válaszokat adni. Ahhoz azonban, hogy megfelelő eredményre jussunk, kellően nagy mennyiségű, a nyelvterület egészét vagy annak jelentősebb szeletét lefedő adatokra van szükségünk. Minél messzebbre megyünk vissza időben, annál kisebb az esélye annak, hogy a fentebb említett feltételnek maradéktalanul eleget tudjunk tenni, hiszen a korai ómagyar korból meglehetősen gyéren állnak rendelkezésünkre a források, és amint már jeleztük, a nyelvemlékek lokalizálása is számos nehézségbe ütközik.
Joggal vetődik fel a kérdés, létezik-e áthidaló megoldás. A válaszom egyértelmű igenlő lehet, noha tudatában vagyok annak, hogy az utóbbi időben a térinformatikával megtámogatott családnévföldrajz sem tud minden tekintetben üdvözítő megoldásokat kínálni. A módszer megnevezésére jobb híján a visszakövetkeztetés terminust használom. Tartalmilag ez ennyit takar, hogy egy későbbi időszak nyelvi korpuszának téri eloszlásából próbálok következtetéseket levonni arra, hol lehetett egy-egy neológ jelenségnek a góca, illetőleg miként modellálható az újítás földrajzi terjedése. Munkámat nagyban könnyíti, hogy két, egymástól mintegy háromszáz évnyire eső időszelet összevetésére nyílik lehetőségünk. Ehhez természetesen azt kell feltételeznünk, hogy a viharos történelmi, valamint a felgyorsult belső és külső migrációs változások időszakát leszámítva a nyelv történetében általában nem következnek be hirtelen, robbanásszerű, az egész nyelvterületet érintő mozgások, átrendeződések. Ebből következőleg a nyelvföldrajzban is egyfajta állandóságot feltételezhetünk. Különösen akkor, ha nagy mennyiségű adat áll rendelkezésünkre.
Az alább bemutatandó két családneves korpusznak az a nagy előnye, hogy egy adott időmetszetben az egész nyelvterületről / országból (mutatis mutandis) nagy mennyiségű, lokalizálható adat vizsgálatára nyílik lehetőségünk, szemben az egyéb forrásokkal, amelyeket vagy a területi határok korlátozott voltával, vagy a reprezentativitás hiányával, avagy mindkettővel minősíthetünk.
Az állandóságot az idő előrehaladtával a jelenségek terjedése és a népességmozgás fogják némileg átrendezni. A továbbiakban az elmondottak igazolására fogunk néhány olyan példát megszemlélni, amelyek alapján állapotokat tudunk megszemlélni, illetőleg folyamatokat modellálni. Mielőtt erre sor kerülne, elöljáróban röviden szólnunk kell az adatbázisokról.
2. Amint fentebb jeleztem, a névföldrajzi vizsgálatokhoz két időszelet családneves korpuszát foghatjuk vallatóra. Az egyiknek az adatai a Magyar Királyság területén elvégzett 1720-as országos összeírásból, a másikét a Közigazgatási és Elektronikus Közszolgáltatások Központi Hivatalának 2009-es népesség-nyilvántartásából származnak. Mindkét adatbázis korpusza strukturálva és előkódolva teszi lehetővé az egymással összetartozó adathalmazok lekérdezését. Az 1720-as összeírásból (OrszÖsszír. 1720/2012) mintegy 179 adóköteles személy családneve áll rendelkezésünkre. Döntő többségük férfinév (lásd részletesebben Vörös 2013, 34., 57–58. p.). Azt persze egyéb támpontok híján közelebbről nem lehet meghatározni, hogy mennyi ebből a születési név. Azt sem tudni pontosan, hogy a korabeli migráns népesség új közösségben kapott ragadványnevei mennyiben tekinthetők egyenértékűeknek a családnevekkel (vö. Vörös 2013, 130–131. p.). Ugyanakkor a conscriptio minden adata helyhez köthető, így az adattáblák megfelelő előkészítése után a Magyar Királyság hárommilliósra becsült hajdani népessége (vö. Acsády 1896, Dávid 1957) hozzávetőlegesen 5,95%-nyi névállományának téri eloszlására látunk rá (Vörös 2013, 130. p.). Mivel az összeírás az Erdélyi Fejedelemségre sem terjedt ki, ezért keleti irányban be kell érnünk a Partium lakosságának vizsgálatával. Délen a később autonómiával rendelkező horvát-szlavónországi területeket, valamint a hozzájuk tartozó részeket és a határvidékeket, északon a Lengyelországnak elzálogosított tizenhárom szepesi várost és Lubló várát sem írták össze.
Az ezredforduló utáni strukturált korpusz (MMCsA 2009) több mint tízmillió alapadatot tartalmaz. Ez alapján a 2009. január 1-jei eszmei állapot szerint az akkori magyarországi lakónépesség családnévállományára láthatunk rá. A születési nevek mindegyike lokalizálható, éspedig megyék, települések, településrészek, Budapest esetében pedig még utcák szerint is. A korpusz teljességét azért fontos hangsúlyozni, mert a nevek a politikai határokon belüli területek egészét lefedik, ezáltal minden korábbinál alaposabban tudjuk bizonyos jelenségek, pl. hangtani, morfológiai, lexikai, jelentéstani stb. téri tagozódását vizsgálni.
Az 1720-as korpusz adatai is többé-kevésbé egyenletesen fedik le a korabeli Magyar Királyság területét. Az adatok téri eloszlásának meghatározásához a történelmi Magyarország Trianonban feldarabolt, majd a második világháború utáni utódállamok határvonalait hívom segítségül. A mai Magyarország területére esik az adatok 38,02%-a. Szlovákia 36,87%-ban részesedik. Vagyis a két régió területére esik együttesen a nevek 74,89%-a. A fennmaradó mintegy 25% a mai Magyarországgal szomszédos államokban található. Ezek a következőképpen oszlanak meg: a manapság Romániához tartozó Partiumból a nevek 9,88%-át, az ausztriai Burgenlandból 7,61%-át, az Ukrajna fennhatósága alatt lévő Kárpátaljáról 3,67%-át, Vajdaságból 1,54%-át, Szlovéniából 1,36%-át, Horvátországból 0,76%-át, a Lengyelország fennhatósága alá tartozó területekről 0,26%-át vizsgálhatjuk.
3. A korpuszalapú névtani kutatásoknak szinte mindig az első lépései közé tartozik a gyakorisági listák meghatározása. Esetünkben azért van ennek jelentősége, mert korábbról sohasem állt rendelkezésünkre olyan hatalmas személynévállomány, mint amilyet az 1720-as összeírás kínál számunkra. A mennyiségi viszonyokon túl a területiség is figyelemre méltó nóvumokat kínál, hiszen a történeti adatbázisok egyikének segítségével sem látunk rá az ország egész területére.
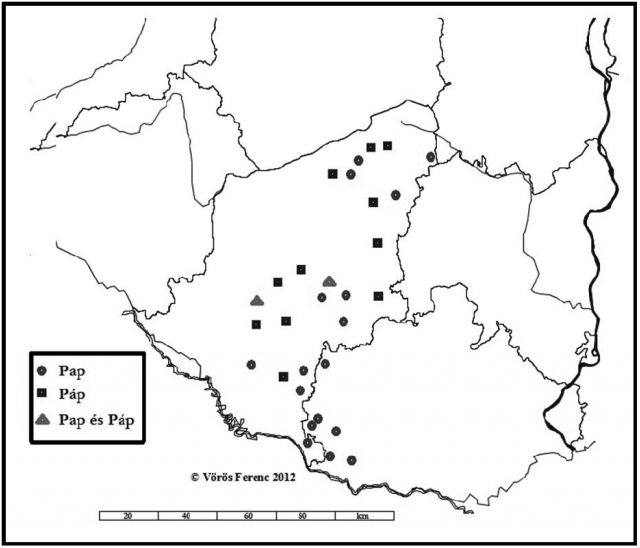
3.1. A gyakorisági lista felállítása korántsem olyan egyszerű feladat, amint az első pillantásra látszik, ugyanis a különféle lexikai típusok alá számtalan ejtés- és/vagy írásképváltozatot lehet besorolni. Még az egyszerűbb hangszerkezetek is meglepően sok változatot takarnak. A három hangból álló Pap-nak1 három, a Kis-nek és Nagy-nak négy-négy, a Tót-nak pedig huszonnégy (sic!) változatát sikerült kimutatni. Az okok többfélék. A változatok nagy számát mindenekelőtt azzal magyarázhatjuk, hogy a 18. század elején nem volt a magyarban egységes írásgyakorlat. Az összeírók a hallott információt az iskolájukban megszerzett ortográfiai ismereteiknek megfelelően rögzítették. Ugyanitt említhetjük, hogy a nevek lejegyzésének elveiről még érintőlegesen sem szólt az 1715. évi LVII. törvénycikk, amelyben elrendelték az első országos összeírást, jóllehet az országgyűlés ennek módját is kidolgozta.2 Magával az összeírás technikai lebonyolításával a 2–4. §-ok foglalkoztak, ám a törvénycikk a kivitelezés mikéntjére sem tartalmazott részletes útmutatást. A családnevek jelenkori írásgyakorlatából kiindulva azt gondolhatnánk, hogy a családi hagyománynak is nagy jelentőséget kell tulajdonítanunk a fentebb említett sokszínűségben. Ezt a feltételezést azonban gyorsan elvethetjük, hiszen számtalan jelből arra következtethetünk, hogy a neveket a conscriptorok bemondás alapján vetették papírra. Ha tehát hagyományőrző írásmódról akarunk szólni, akkor leginkább arra a hagyományra kell gondolnunk, amelyet az összeírók írásgyakorlata takarhat, s korántsem a névgazdák által nemzedékről nemzedékre áttestált családi hagyományra. Ez utóbbit azért is elvethetjük, mert az 1720-as összeírás alapvetően az adóköteles személyek nevét hagyta ránk. Alanyai többségükben a betűvetés tudományában járatlan jobbágyok köréből kerültek ki. Kisebb részben a városi népesség névállományával is találkozhatunk a tékák lapjain, akiknek a műveltségéről ugyan vajmi keveset tudunk, ám sejthetjük, hogy ekkortájt a családnevek írásmódjának változatlan formájú apáról fiúra örökítése ebben a társadalmi rétegben sem mondható általánosnak. Az összeíró íveket a megyék által kiküldött személyek vezették, éspedig latinul. Nincs nyoma annak, hogy a nevek feljegyzésekor figyelembe vették volna a családi hagyományt. Ugyanakkor számtalan példát találunk arra, hogy félrehallott alakokat vetettek papírra. Különösen akkor, amikor a conscriptorok nem rendelkeztek az adott településen és/vagy térségben használatos nyelv, illetőleg dialektus ismeretével, illetőleg a magyarétól eltérő név nyelvi alkatának beazonosításához szükséges nyelvtudással. Mindezek tehát magyarázatul szolgálnak az egyes lexikai típusok alá besorolt nyelvi adatok írásképének sokszínűségére. Az állítás igazolására vessünk egy pillantást a Pap lexikai típusának, illetőleg a Páp változatnak a nyelvföldrajzára!
2. ábra. A Pap és változatai az 1720-as összeírásban (megyénkénti bontásban)
A 2. és 3. térkép (2. és 3. ábra) alapján megállapítható, hogy a Pap a 18. század elején alapvetően a magyar nyelvterülethez köthető, jóllehet nem teljesen egyenletesen fedi le azt. Figyelemre méltó foghíjakat találunk Nyugaton Vas, Zala és Somogy megye egyes térségeiben, Keleten a Tisza és a Maros által határolt területen. A Duna–Tisza közének déli részén jelentkező hiátus megfigyelésem szerint nemcsak e névnél, hanem a többi gyakori lexikai típusnál is jelentkezik (a Kovács, Szabó, Nagy és Tót történeti kartogramját lásd Vörös 2013, 110., 124., 137., 146. p.). Ez a tény tehát valószínűleg eredendően nem a Pap korabeli elterjedtségével, hanem a török pusztítással hozható összefüggésbe.
A Páp adatainak területi tagolódását tanulmányozva szembeszökő, hogy azok kivétel nélkül a történelmi Somogy megye területén bukkannak fel. A változatok efféle területi eloszlását esetünkben alapvetően háromféle okra vezethetjük vissza. Az egyik, hogy sajátos, csak az adott térségre jellemző ejtésmóddal van dolgunk. A másik, hogy az adat feljegyzőjének ortográfiai gyakorlata áll a hátterében. A harmadik, hogy a conscriptor sajátos anyanyelvjárási tudása alapján „hall félre” valamit. Elvileg az sem zárható ki, hogy a három tényező együttesével kell számolnunk. Az oknyomozásnak e pontján azonban nem téveszthetjük szem elől, hogy kik is végezték el Somogyban az összeírást. Ha ennek utánajárunk, a fentebbi felvetések közül legkézenfekvőbbnek a harmadik változat tűnik racionális magyarázatnak, ugyanis ezzel a feladattal a Heves megye küldöttei lettek megbízva. Meglehet, talán a palóc nyelvterületen szocializálódott Heves megyei fül hallhatta bele a köznyelvi a-ba az illabiális ™ hangot, amelyet aztán megfelelő hangjelölés hiányában hosszú á-val adhatott vissza (a palóc nyelvjárási régió tömbjeinek 20. századi területiségéről lásd Juhász 2001, 282. p.). Mindazonáltal figyelemre méltó, hogy a Páp-nak mint változatnak a térbeli eloszlása olyasféle, mintha egy összeíró kétnapi járóföldnyi Somogy megyei útját rajzolná ki Balatonendréd, Kőröshegy, Látrány, Andocs, Igal, Baté, Juta, Mezőcsokonya, Kutas, Szabás, Csököly, Homokszentgyörgy érintésével.3 Nem tudni, hogy valóban ebben a sorrendben történt-e az adóalanyok, illetőleg a falusi elöljárók kikérdezése az adóköteles személyekről, de annyi bizonyosnak tűnik, hogy a Pap szótári típusán belül csak a Somogy megyei tékák ívein találkozni a jelenséggel (lásd 4. ábra). Egyébiránt az is figyelemre méltó, hogy a hagyományőrzőnek számító hosszú p-s alakból egy sem bukkant föl a Somogy megyei összeíró íveken. Megjegyzem a 4. számú térképre vetített 42 adatból 27-et Pap, 15-öt Páp alakban hagytak ránk az 1720-ban Somogy megyében ténykedő conscriptorok.
3. ábra. A Pap és változatai az 1720-as összeírásban (településenkénti bontásban)
4. ábra. A történelmi Somogy megyében felbukkanó Pap és Páp változatok földrajzi eloszlása az 1720-as összeírásban (a jelenkori közigazgatási beosztásra vetítve)
3.2. A tizenkét leggyakoribb név között egy sem akad, amelyet a Kázmér-féle családnévszótár alapján ne a magyarból eredeztetnénk, jóllehet többnek is kölcsönszónak tekinthető közszói etimon van a hátterében. Ezek némelyike korai átvétel. Közöttük olyanokat is találni, amelyek akkor kerültek be nyelvünkbe, amikor a magyarban még családnevek sem léteztek. Ilyen pl. a Kovács és a Pap. Mindkettő kora ómagyar kori, a szláv dialektusok valamelyikéből származtatható átvételre vezethető vissza. Mikorra az egyelemű névrendszerből kezdetét vette a többelemű névrendszerre történő váltás, addigra mindkettő teljes mértékben nyelvünkbe integrálódott, majd családnévvé vált. Csupán egyetlen olyan lexikai típust találunk az 1. táblázatban, amelynek eredeztetésekor a magyaron kívül más nyelvek is szóba kerülhetnek: a Kovács-ot. Ez utóbbi ugyanis családnévként a környező szláv nyelvekből is levezethető. A kétféle eredetréteg azonban a Kovács esetében szinte szétválaszthatatlanul egybeolvad a történeti és jelenkori korpuszunkban. Az egyes adatokról csak genealógiai vizsgálatokkal lenne kideríthető, hogy a magyar vagy a szláv eredetréteghez tartoznak-e. Az etnikai viszonyok ismeretében azonban némi fogódzót jelenthet a névföldrajz, ugyanis a magyar, illetőleg szláv népesség által tömbszerűen lakott térségekben az adatok téri eloszlása kellő alapot teremt bizonyos következtetések levonására. Mielőtt erről meggyőződnénk, vegyük szemügyre a tizenkét leggyakoribb családnév listáját! Tegyük ezt oly módon, hogy párhuzamot vonunk a jelenkori adatokkal!
1. táblázat. A 12 leggyakoribb családnév 1720-ban és 2009-ben
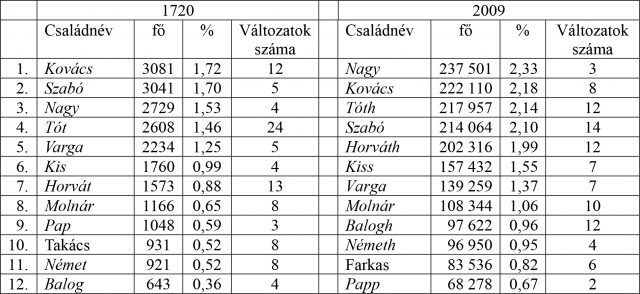
Az adatbázisok 12 leggyakoribb nevének párba állításakor több dolog is azonnal szembeötlik. 1. A sorrendiség tekintetében csupán a hatodik helyen található Kis és a nyolcadik helyen álló Molnár pozíciója egyezik meg, a többi lexikai típusé nem; 2. A két idősík listája csupán egy-egy lexikai típusban tér el egymástól: az 1720-asban a Farkas-t, a 2009-ben viszont a Takács-ot nem leljük meg; 3. A listák élén álló négy név pozíciója ugyan eltér egymástól, de mindkét időszeletben ugyanazt a négy nevet találjuk; 4. Az adatbázisok egészéhez képest megadott százalékos értékek léptékük tekintetében többnyire nem mutatnak jelentős különbséget; 5. A várakozásokkal ellentétben nem a történeti réteg lexikai típusaiban találjuk a legtöbb változatot, habár a Tót-nak ebben az időszeletben az összes többi szótári egységnél lényegesen változatosabb írásképeit hagyták ránk a tékák lapjai (a változatokat a gyakoriságukkal együtt lásd Vörös 2013, 98. p.).4 Egyébiránt a jelenkori korpuszban a gyakorisági lista élén álló nevek közül a legtöbb változatát a Szabó-nak, majd a Balogh-nak, Horváth-nak és a Tóth-nak sikerült kimutatni. Ezek helyesírásunk szűkebben értelmezett hagyományőrző jellegének tanulmányozását teszik lehetővé. Egy részük a magyar ortográfia-történet különféle korszakaihoz vezet vissza bennünket. A Szabó ~ Zabó kettősségének szókezdő z-je például az /sz/ jelölésének kora és késő ómagyar kori emlékét őrzi. Egyes feltételezések szerint az, hogy a nyelvemlékes kor első időszakában a z és sz hangpár közös jele a z volt, ófelnémet hatásra vezethető vissza (vö. Korompay 2004, 282. p.). A cs hangértékű ch a szóvégen ugyancsak olyasféle, családnevek által megőrzött archaizmus, amelyet viszont az ófrancia írásgyakorlat ómagyar kori hatásával magyarázunk (vö. Korompay 2004, 282. p.). Ez utóbbit találjuk például a Kovách-on.
Érdekes jelenség a fentebb már említett Pap szóvégi hangzójának geminációja. Az eddigi kutatások nem fordítottak rá különösebb figyelmet. Sem azt nem tudjuk pontosan, hogy a jelenség melyik nyelvtörténeti korszaknak volt az újítása, sem azt, hogy a nyelvterület mely részén bukkantak fel először a hosszú p-vel lejegyzett adatok. Ezzel kapcsolatban Korompay Klára így fogalmaz: „Feltűnő gyakran találkozunk bizonyos családnevekben szóvégi betűkettőzéssel: Papp, Kiss, Sass, Veress. Ez azért feltűnő, mert a gemináció hangzóközi helyzetben szokott bekövetkezni. A neveken belül feltehetően szerepet játszik az adott elem rövidsége: az egy szótagú nevek mintha különösen kedvelnék a betűkettőzést” (Korompay 2010, 62. p.). Korompay arra is utal, hogy a névvégi gemináták Ördög Ferencnek a 18. századi Zala megyei korpuszából már kellően nagy számban kimutathatók (vö. Ördög 2008, 281. p.).
3.3. Érdekes kísérletnek ígérkezik, hogy a Pap hosszú p-s írásképváltozatainak nyelvföldrajzi eloszlását két időszelet viszonylatában összevessük. Noha a két adatbázis mennyiségileg jelentősen különbözik egymástól, a szóban forgó lexikai típus összkorpuszon belüli részesedése nem mutat akkora különbséget, hogy ennek következtében az összevetés eredményeit fenntartásokkal kelljen fogadnunk. Az 1720-as összeírás 1048 adata 0,59%-át, a 2009-es 69 722 neve 0,68%-át teszik ki a teljes családnévanyagnak.
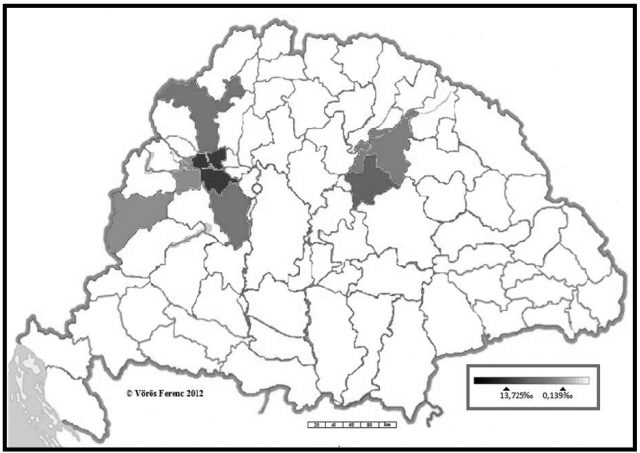
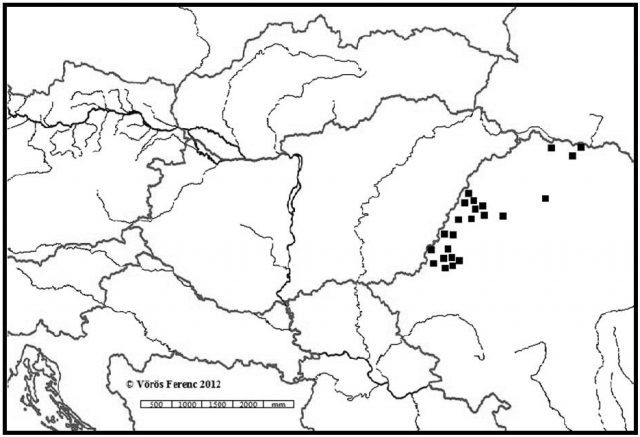
A 18. század elejéről a geminátás változatból 78 adatot sikerült kimutatni. Ezek a lexikai típus egészének mindössze 7,44%-át teszik ki.5 Ezzel szemben az ezredfordulós korpuszban a hosszú p-s változatok teszik ki a Pap lexikai típusának döntő többségét (77,33%). A számok arra engednek következtetni, hogy a Pap esetében országos viszonylatban a névvégi gemináta – mint ortográfiai megoldás – az utóbbi háromszáz évben vált elterjedtebbé. Azért az óvatos fogalmazás, mert pontosan nem tudni, hogy a névvégi p lejegyzéskori kettőzésében mekkora szerepet játszott az összeírók személye, pontosabban az általuk favorizált ortográfiai gyakorlat. Ha pedig ez utóbbi ténnyel is számolunk, akkor arra ugyancsak tekintettel kell lennünk, hogy az adott térséget összeíró személyek honnan érkeztek az egyes megyékbe, illetőleg hol sajátították el a betűvetés tudományát. A jelenség a 18. század elején a legkoncentráltabban Komárom megyében mutatható ki (42 adat – 13,726‰). Az összeírást itt Torna megyei conscriptorok végezték. Ezt követi Hajdú (8 adat – 7,843‰), Fejér (4 adat – 1,946‰), Nyitra (18 adat – 1,712‰), Szabolcs (2 adat – 0,864‰), Győr (2 adat – 0,493‰) és Vas megye (2 adat – 0,139‰). A Hajdú kerületben és Szabolcsban Fejér megyei, Fejér megyében nógrádi, Nyitra megyében ungi, Győr megyében nyitrai, Vas megyében gömöri összeírók vetették papírra az adatokat. Ugyan az összeírók földrajzi hovatartozása első pillantásra kellően szóródik, ám ha figyelmesebben szemügyre vesszük a kiküldő megyék elhelyezkedését, akkor alapvetően két góc rajzolódik ki előttünk a korabeli Magyar Királyság térképén. Földrajzilag többé-kevésbé mindkettő egybeesik a Pap hosszú p-s adatainak felbukkanási helyeivel (kivétel ez alól Vas megye, amelynek két összeírója Gömör megyéből lett kiküldve).
5. ábra. A Pap hosszú p-s változatai az 1720-as összeírásban (megyénkénti bontásban)
6. ábra. A Pap hosszú p-s változatai az 1720-as összeírásban (településenkénti bontásban)
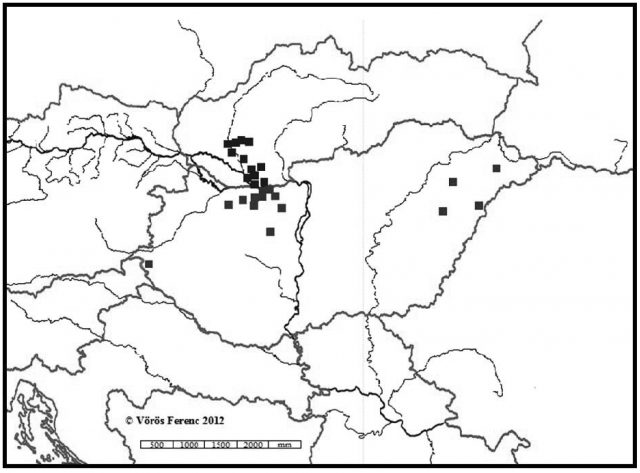
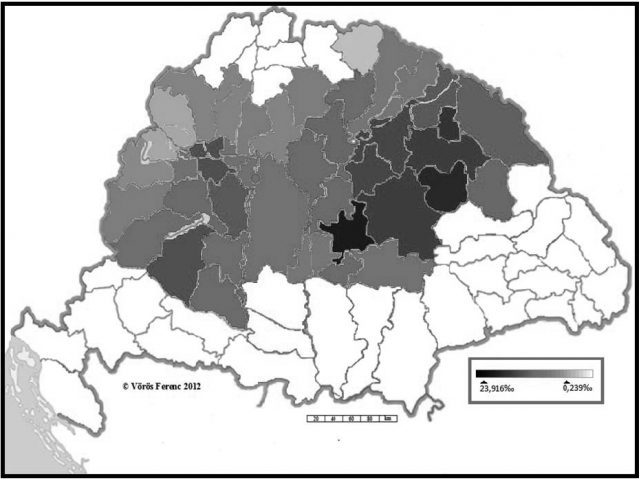
Háromszáz évet ugorva azt tapasztaljuk, hogy a Pap családnév hosszú p-s változata a mai politikai határokon belül szinte az egész nyelvterületet uralja (lásd 7. és 8. ábra), ám leginkább az ország keleti felében, azon belül is az északkeleti térség két megyéjében, Hajdú-Biharban, valamint Szabolcs-Szatmár-Beregben van jelen legerőteljesebben.6 A 7. ábra azt is jelzi, hogy a Dunántúlon leginkább a Veszprém, Somogy, Tolna és Baranya által határolt térségekben találkozni Papp-okkal. Megjegyzendő, hogy a mintegy 15 ezer rövid p-s adat érdemben nem befolyásolja a most bemutatott jelenségtérkép tájegységek szerinti elszíneződését. A jelenkori térképeken feltűnő a Duna–Tisza közének hiátusa, amelyre egyéb támpontok híján egyelőre nem tudunk más magyarázattal szolgálni, mint a százötven éves török pusztítás valamiféle kései lenyomata.
7. ábra. A Pap hosszú p-s változatai a 2009-es korpuszban (megyénkénti bontásban)
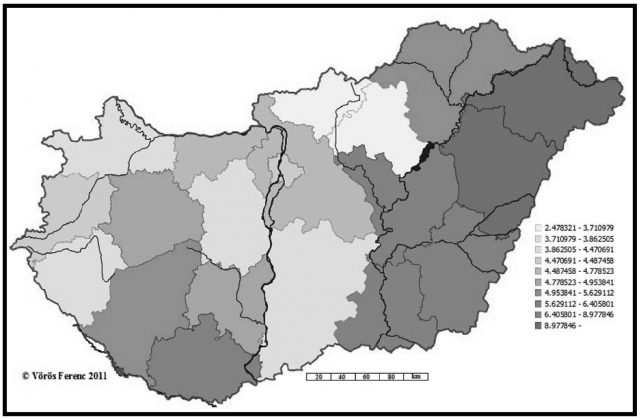
8. ábra. A Pap hosszú p-s változatai a 2009-es korpuszban (településenkénti bontásban)

3.4. A Kovács családnév történeti és jelenkori nyelvföldrajzával több korábbi munkámban is foglalkoztam (lásd Vörös 2009, 196. p.; 2013, 104–114. p.). Éppen ezért a közszói etimonnal kapcsolatos tudnivalókat e helyütt csak röviden érintem.
Az etimológiai szótárak a kovács közszó eredeztetésekor egyöntetűen úgy fogalmaznak, hogy az korai átvételként a déli szláv dialektusokból kerülhetett át a magyarba (vö. TESz, EWUNg). Szótörténeti szempontból fölöttébb érdekes: a szláv eredetű kovács szavunk mellé a (vas)verő nemcsak társult, hanem jószerivel ki is szorította azt a nyelvhasználatból (Moór 1954, 72. p.). Megjegyezem, Rubinyi Mózes a moldvai csángók köréből személyek megnevezésére szolgáló közszóként említi a vaszverő-t (sic!), amely ott a kovácsmesterségre járatos kifejezés (Rubinyi 1901, 171. p.). Bárczi Géza szerint a kovácsmesterségre a verő mint közszó még a 17. században is használatos volt (vö. Bárczi 1967, 289. p.). Ez utóbbi azért érdekes számunkra, mert Bárczi állítása alapján azt várnánk, hogy foglalkozásnévi eredetű családnévként mind az 1720-as, mind pedig az ezredforduló utáni korpuszban viszonylag nagy számban találunk ilyen adatokat. Ezzel szemben a 18. század eleji forrásból mindössze négy ide vonható nevet sikerült kimutatni: valamennyi a nyelvterület keleti feléről származik. Közülük három egyértelműen a kötélverő mesterséggel hozható kapcsolatba: Kotélverő (Szatmárnémeti – rom. Satu Mare; Szatmár megye), Kötélverö (Mezőtúr; Heves és Külső-Szolnok megye), Kőtélverő (Érsemjén – rom. Şimian; Bihar megye), Verö (Nyíracsád; Bihar megye). Az érsemjéni puszta Verö természetesen nem jogosít fel bennünk arra, hogy magát a névben rejlő mesterséget beazonosítsuk, hiszen annak közszói etimonja hajdan a vasverő mellett egyebeken túl a kötélverőre, rézverőre stb. is utalhatott. Természetesen a jelenkori korpuszban is találkozni verő-kkel. Nem egy közülük többes tagolódású családnév részeként vagy valamilyen összetétel utótagjaként tartalmazta a keresett szót (Házverő-Szabó [6], Házverő-Török [4], Házverő Szabó [3], Házverőszabó [1], Verő-Gergye [1]; Kötélverő [71], Kincsverő [29], Hadverő [12], Dióverő [5], Kőtélverő [3], Rézverő [3], Kötélverö [2], Kötelverő [1]). Ezenkívül 251 puszta Verő-t is találtam. Mindazonáltal elgondolkodtató, hogy a Verő-ből relatíve csak ilyen kevés családnév adatolható az ezredfordulós magyar névállományban.
A Kovács – amint fentebb az 1. táblázatban láttuk – a 18. század első felében a leggyakoribb családnév volt az adóköteles személyek körében. Tizenkét írásképváltozatát sikerült kimutatni a korpuszból. Ezek gyakoriságuk sorrendjében a következők: Kovács (2093), Kovacs (701), Kováts (161), Kouács (50), Kovats (40), Kovach (11), Kóvács (11), Kovacz (6), Kovácz (4), Kouacs (2), Kovac (1), Kóvacs (1). Megjegyzendő, hogy a cs hang ts-ses, cz-s, illetőleg ch-s jelölési módja a korabeli, felekezeti megoszlást mutató írásgyakorlattal hozható összefüggésbe. A ts-esek jellegzetesen a középmagyar kori protestáns, a cz-sek és ch-sak a katolikus helyesírási gyakorlat továbbvitelének tekinthetők (vö. Korompay 2010, 62–63. p.). Ez utóbbi jelölési módot egészen a kancelláriai helyesírási gyakorlatig tudjuk visszavezetni. Egyébiránt a cs-s jelölési mód alapvetően 17. századi katolikus újításnak számít. Ha a Kovács névvégi hangja jelölésmódjainak gyakoriságát alaposabban megszemléljük, azonnal feltűnik a cs-s változatok dominanciája (92,79%). Ez arra enged következtetni, hogy a családnevek írásában már jóval a 19. századi eleji nyelvújítási vita előtt háttérbe szorultak a középmagyar kori felekezeti különbségeket továbbvivő archaikus jelölési módok.
A továbbiakban a lexikai típus adatainak területi eloszlását fogjuk térképek segítségével tanulmányozni. A 9. és 10. ábrából egyértelműen kiolvasható, hogy a név adatai lényegileg az egész Magyar Királyság területét lefedik. Kivétel ez alól a töröktől nemrégiben visszafoglalt területek egy része. Mindenekelőtt a Duna–Tisza közének délebbi területei, valamint a Tisza alsó folyásától keletre. Továbbá kisebb hiátusokkal találkozhatunk a mai Szlovákia területén Pozsony, Szepes és Sáros megyében. Kárpátalján Máramarosban egyetlen adata sem bukkant fel a névnek, holott ez utóbbi térségben jelentős számú szláv népességgel számolhatunk. A 9. ábra alapján megerősítődni látszik az etimológiai szótáraknak az az állítása, hogy a név alapját képező közszó elsősorban a déli szláv dialektusokból kerülhetett át a magyarba, jóllehet a térkép alapján az északi szláv dialektusokat sem zárhatjuk ki kategorikusan a forrásnyelvek közül. Ami azonnal szembeötlő, hogy a Kovács különösen nagy koncentrációban van jelen a Duna folyásától nyugatra eső megyék közül a Somogy, Zala, Veszprém, Zala és Tolna által határolt régióban. Ez alapján joggal vetődik fel a kérdés, hogy a név dunántúli koncentráltsága összefüggésbe hozható-e azzal, hogy a honfoglaló magyarok a Dunántúlon jelentős számú szláv népességet találtak, akik nyelvi asszimilálódásának egyfajta szubsztrátumaként fogható fel a kovács közszó elterjedtsége. Hogy melyik honfoglalás kori pannóniai szláv dialektus lehetett az átadó, erre nézvést a TESz és az EWUng is óvatosan fogalmaz, amikor a déli szláv eredetet valószínűsíti. Főként hangtani kritériumokra támaszkodik, nyelvföldrajzi támpontokat nem vesz számba. Mindazonáltal tudnunk kell, hogy a kovács magyarba kerülésekor a Pannóniában beszélt dialektusok hangtani sajátosságait alapvetően nyelvünkbe került szláv kölcsönszavak segítségével tudjuk rekonstruálni. Az átadás-átvétel irányának hangtani alapokra helyezett meghatározása azonban azért ütközik nehézségekbe, mert ahogy egyik recenziójában Zoltán András fogalmaz: „a későbbi horvátot, szlovént és szlovákot jellemző hangtani vonások olyan kombinációban fordultak elő, ami ma együttesen egyetlen szláv nyelvben sem található meg” (Zoltán 2004, 674. p.). A Dunántúlon létezhetett viszont egy olyan szláv dialektus, amely a bolgárszlávval hozható rokonságba. Ennek hangtani példázataként szokás a gerencsér foglalkozásnevünket említeni, amely etimonja sem a szerbből, sem a horvátból, sem a szlovénből nem mutatható ki, csakis a bolgárból. Megjegyzem, az ómagyar kori közszói átvételre visszavezethető Gerencsér családnévnek mind a labiális, mind az illabiális változatai máig döntően a Dunántúlhoz köthetők (vö. Vörös 2010, 170–175. p.). Napjainkban tehát a szlavisták Simonyi Zsigmondnál óvatosabban fogalmaznak. Simonyi ugyanis a kovács közszóról határozottan állítja, hogy azt egyenesen a szlovénból vettük át (vö. Simonyi 1906, 400. p.; a szlovén eredeztetésről lásd még Asbóth 1900, 323–324. p.).
Visszatérve az eredeti gondolatmenetre: az elmondottakból egyenesen következik, hogy pusztán a Kovács nyelvföldrajzának vizsgálatával nem tudunk racionális magyarázattal szolgálni a fentebb említett, a magyar királyság szláv nyelvterületein megfigyelhető nyelvföldrajzi hiátusaira. Ehhez behatóbban kellene vizsgálni az egyes térségek legfrekventáltabb neveit, amelyek regionális szinten háttérbe szoríthatták a Kovácsot. Annyi azonban bizonyos, hogy a török kiűzése után a felső-magyarországi területekről déli irányban meginduló népességmozgással számos, az északi szláv nyelvekben (leginkább a szlovákban) keletkezett Kovács keveredhetett a magyarban létrejött családnevekkel.7 Ez a magyarázata annak a fentebb hangsúlyozott kitételnek, hogy a Kovács esetében csak genealógiai vizsgálatokkal lehetne korrekt módon szétválasztani a szláv és a magyar eredetréteghez tartozó adatokat.
9. ábra. A Kovács szótári típusának területi eloszlása az 1720-as összeírásban (megyénkénti bontásban)
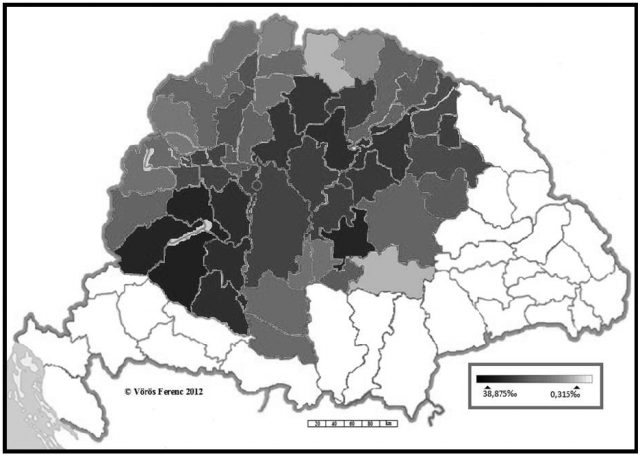
10. ábra. A Kovács szótári típusának területi eloszlása az 1720-as összeírásban (településenkénti bontásban)
3.5. A továbbiakban a népességmozgás tanulmányozásához kívánok adalékkal szolgálni az Árgyelán családnév történeti és jelenkori nyelvföldrajzának vizsgálatával.
Az Árgyelán alapja egy honfoglalás korabeli tájnevünkkel, az Erdéllyel hozható kapcsolatba. Az ’erdő elü, erdő előtti, erdőn túli’ jelentésű Erdély tájnév különféle hangváltozásokkal vette fel mai hangalakját (Kúnos 1885, 98. p.; Horger 1910, 342. p.; Hefty 1911, 155. p.; Pais 1912, 125. p.; Tagányi 1913, 148. p.; Alexics 1914, 403. p.; Laziczius 1941, 274. p.; Szabó T. 1943, 73. p.; Juhász 1984, 232–233. p.; Hajdú 1990, 80. p.; Kiss 1996, 442. p.). Rekonstruált hangalakja: *Erdeuelu. Egyesek szerint a magyar tájnév a székely nyelvjárások valamelyikéből került át kölcsönszóként a románba (vö. Iordan 1983, Ionescu 2004), éspedig onnan, ahol a szókezdő hangot legalsó nyelvállású (ún. nagyon nyílt) ä-vel ejtették (Ärdel). A helynév d-nek gy-vé palatalizálódásával, valamint a románban ilyenkor szükséges ’onnan / oda való’ jelentésű -an / -ean(u) helynévképző hozzátoldásával integrálódott az átvevő nyelvben. Eszerint az így keletkezett melléknév volt az Argyelan(u) ’Erdélyből származó, erdélyi’ román családnév alapja.
Az etimológia tárgyalásakor nem kerülheti el a figyelmünket, hogy a magyarországi beás cigányok három dialektusa közül az egyiket az árgyelánok alkotják (Bíró 2006, 62. p.). A dialektus beszélői jellemzően Baranya (Lakatos 2006, 112. p.), illetőleg az azzal határos Somogy, Tolna megye területén élnek. Nyelvüket a 19. századi román nyelvújítás előtti archaikus változatként tartjuk számon. A mai Magyarország területére egyértelműen migráció révén kerültek át.
11. ábra. Az Árgyelán szótári típusának területi eloszlása az 1720-as összeírásban (megyénkénti bontásban)
Az árgyelánok és a szóban forgó Árgyelán családnév között nem kell okvetlenül szoros összefüggésre gondolnunk. A névadás logikája ugyanis a népnévi eredetű családnevek esetében általában azt diktálja, hogy a közösségből kiszakadókat, földrajzilag távol(abb)ra kerülőket ruházzák fel az új közegben ezzel a ragadványnévszerű jelzővel. Az sem kizárt, hogy az árgyelánokhoz külsőleg és/vagy belsőleg hasonlító, esetleg velük valamilyen kapcsolatba kerülő személyeket kezdik így nevezni. Ezek a tények tehát óvatosságra intenek bennünket, amikor a családnév nyelvföldrajzát tárgyaljuk.
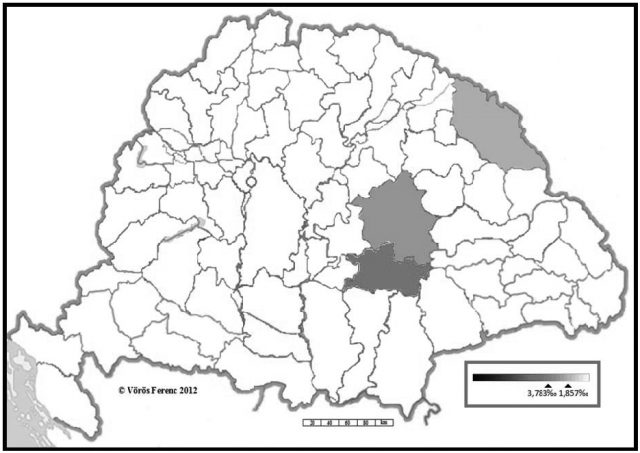
Az 1720-as összeírás korpuszában az Árgyelán lexikai típusa alá 35 adatot sikerült besorolni. Ezek hét különböző ejtés- és/vagy írásképváltozatot takarnak. Íme: Ardilan (12), Ardilán (10), Ardelan (5), Ardillan (4), Ardelán (2), Ardelán, Ardilla (1), Ardilyan (1). Rajtuk kívül egy olyat is találtam, amely magyar névképzésnek tekinthető, és minden valószínűség szerint a székelység körében használatos igen nyílt ä-s ejtést takar (Ardéli). Ezt a dolog természetéből adódóan az Erdélyi szócikkébe tartozónak kell tekintenünk. A történeti korpusz nyelvföldrajzi érdekességeként említhető, hogy az alapvetően a Partium három megyéje – Arad (12 adat – 3,783‰), Bihar (18 adat – 1,975‰) és Máramaros (5 adat – 1,857‰) megye – között oszlik meg. Egyetlen adat sem lépi át a mai Magyarország politikai határait. A névgazdák etnikai hovatartozásáról semmi közelebbit sem tudunk, ám a név gyaníthatóan magyar és román névgazdákat is takarhatott, különösen az etnikailag vegyes Arad és Bihar megyében.
12. ábra. Az Árgyelán szótári típusának területi eloszlása az 1720-as összeírásban (településenkénti bontásban)
A jelenkori korpusz adatai az ország minden megyéjében, illetőleg a fővárosban is megtalálhatók. Igaz, minél nyugatabbra megyünk, annál kisebb koncentrációban van jelen a név az egyes térségekben. Az 1204 adat szórtságát mi sem jelzi jobban, mint hogy a névnek tizenhat változatát mutatta ki a MMCsA keresője: Árgyelán (790), Ardelean (117), Argyelán (102), Ardeleán (50), Árgyellán (29), Ardelán (26), Árdeleán (23), Argyilán (14), Árgyilán (12), Árdelán (10), Argyel (9), Argyellán (9), Ardeleanu (7), Árgyel (4), Ardel (1), Árgyél (1). A változatok sokszínűségét Hajdú Mihály is az adatok nagyfokú földrajzi szórtságával magyarázza (Hajdú 2010, 38. p.). A Hajdú-féle családnév-enciklopédia a név jelenkori névföldrajzával kapcsolatban meglepően pontos eligazítást nyújt, noha szerzője csupán gyűjtéseken alapuló megfigyelésekre támaszkodhatott, hiszen nem ismerte azokat a kartogramokat, amelyeket e helyütt az olvasó rendelkezésére bocsátok.
A 14. ábra alapján megállapítható, hogy a lexikai típus adatai két délkelet-magyarországi megyében sűrűsödnek. A név a Partiummal határos régióban viszonylag összefüggő észak–nyugati sávot fed le, de tulajdonképpen kisebb-nagyobb foghíjakkal egész Békés és Csongrád megyében jelen van. A főváros környékén ugyancsak összefüggőbb terület rajzolódik ki, jóllehet a név koncentráltsága itt lényegesen kisebb, mint az említett dél-alföldi megyékben. A magyarországi romák által lakott térségekkel az Árgyelánnak nem mutatkozik átfedése, különösen nem a beás cigányok által lakott Dél-Dunántúlon.
Az Árgyelán nyelvföldrajzának tanulmányozása alapján arra a következtetésre kell jutnunk, hogy a név a román népességnek a 18. század után felgyorsult népességmozgása révén került be a mai magyar(országi) névkincs jövevényrétegébe. A különféle hangváltozások nagyban hozzájárultak a nyelvi integrációjához. A mai magyar nyelvérzék számára homály fedi, hogy etimológiailag Erdély tájnevünkkel van kapcsolatban. Ugyanakkor a nyelvész számára kiválóan példázza a kölcsönzés és a visszakölcsönzés nyelvi és extralingvális sajátosságait.
13. ábra. Az Árgyelán szótári típusának területi eloszlása az 2009-es korpuszban (megyénkénti bontásban)
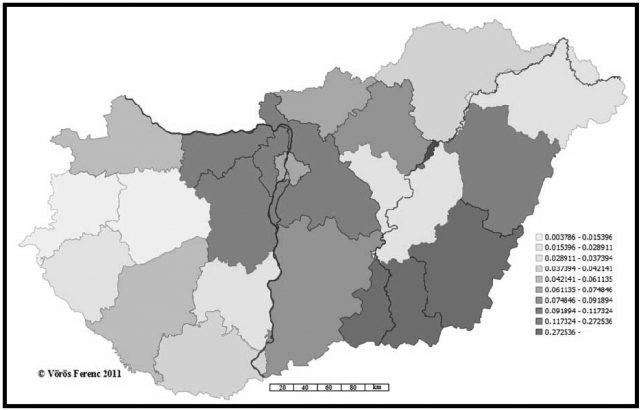
14. ábra. Az Árgyelán szótári típusának területi eloszlása az 2009-es korpuszban (településenkénti bontásban)
3.6. Végezetül egy olyan példát szeretnék bemutatni, amely a 18. század eleji nyelvhatár hozzávetőleges meghatározásához nemcsak a szociolingvisták, hanem a rokon szakmák képviselői számára is támpontokat kínálhat. Ehhez a 3.2. pontban tárgyalt leggyakoribb nevek közül választottam ki egy olyat, amelyet minden kétséget kizáróan magyar etimonként tarthatunk számon.8
A választásom a Nagy családnévre esett, amely minden kétséget kizáróan magyar névképzésnek tekinthető, sőt a benne rejlő közszóról is nagy valószínűséggel állítható, hogy az belső keletkezésű magyar lexikai egység, jóllehet etimológiai szótáraink bizonytalan, talán a finnugor korig visszavezethető örökségként kezelik a nagy közszót (vö. TESz, EWUng).
A fentebbi fejezetekben elmondottak alapján a Nagy családnév 18. század eleji gyakorisága nem ér bennünket váratlanul. Különösen akkor nem, ha figyelembe vesszük, hányféle motiváció állhat az ide sorolandó nevek hátterében. Elsőként említhetjük a nemzedékviszonyító szerepét, ugyanis a zártabb közösségekben máig természetes, hogy családon belül az idősebb nemzedék tagjait a Nagy ragadványnévvel említik. Másodikként vehetjük számba azt a motivációt, amelyet az etimológiai szótárak alapján a következőképpen adhatunk meg: ’jelentős szerepű, kiváló személy, hatalommal rendelkező, magas rangú, vezető ember stb.’ (vö. EWUng, TESz). Analógiákként idézhetjük azokat a közszói összetételeinket, amelyekben nagy elő- vagy utótagot találunk, pl. nagyapa, nagybácsi, nagymama, nagynéni; (falunagy >) fónagy, hadnagy, násznagy, őrnagy, várnagy; stb. (vö. Moór 1949, 21. p.; Hajdú 2003, 775. p.). Ezzel kapcsolatban említhetjük Penavin Olga szlavóniai gyűjtéséből, hogy a 19. század közepén Kórógyon az azonos nemzedékhez tartozó egyező nevű gyermekek megkülönböztetése is a Kis és Nagy jelző segítségével történt. Penavin ehhez még annyit tesz hozzá, hogy a „Nagy ragadványnév a családból kivált idősebb testvér, a Kis pedig a fiatalabb testvér nevének jelölője lett (vö. nagyobbik uram = az uram bátyja, kisebbik uram = az uram öccse)” (Penavin 1958, 477. p.). A fentebb elmondottakat látszik megerősíteni Szabó T. Attilának a 16–17. századi erdélyi nemzedékviszonyító funkciójú családnevekről publikált írása (Szabó T. 1967).
Végül a Nagy motivációinak számbavételekor azt sem hagyhatjuk figyelmen kívül, amire a laikus nyelvérzék alapján a legtöbben gondolnak: vagyis hogy a valamikori felmenő termetére (magasság, erős testalkat) utalás is nem egy ide tartozó családnév kialakulásában közrejátszhatott. Hajdú Mihály szerint a Nagy vagyoni helyzetre is utalhatott (Hajdú 2003, 775. p.), jóllehet talán ezzel a motivációval a legkevésbé szokás számolni.
A leggyakoribb nevek esetében okkal vetődik fel a kérdés, miként tölthették be identifikáló funkciójukat, ha nemcsak a makro-, de a mikroközösségen belül is az átlagosnál lényegesen többször találkozhatunk velük. Nyilvánvaló, hogy elsősorban a mikroközösségen belüli szerepüket kell vizsgálnunk, és csak másodsorban azt, hogy a beszélőközösség egészén belül hogyan lehetett a sok azonos nevű személy között eligazodni. A Nagy és a Kis nemzedékviszonyító funkciója kapcsán azt gondolhatnánk, hogy a 18. század elején – amikor már léteztek öröklődő családnevek, ám a születéskor kapott családnév korántsem kísért végig mindenkit az életútján – a szóban forgó összetevők mint ragadványnévszerű névrészek tömegesen, de legalábbis nagy számban adatolhatók az 1720-as korpuszból. Ezzel kapcsolatban elsőként azt vizsgáltam, miféle családnevek előtt találkozhatunk nemzedékviszonyító-gyanús (a továbbiakban az egyszerűség kedvéért: nemzedékviszonyító) Nagy-okat és Kis-eket a többes tagolódású névegyüttesekben. A 722 ide sorolható adatból 114 Kis (15,79%), továbbá 71 Nagy (9,83%) névrészes adatot sikerült kimutatni. Csupán érdekességként említem, hogy mindkét csoportban az ún. apanévi eredetű családnevek mellett találtam a legtöbb nemzedékviszonyító Kis-t (55,28%) és Nagy-ot (61,97%). Lényegesen kevesebbszer szerepeltek foglalkozásnevek (Kis: 22,81%; Nagy: 12,68%), népnévi eredetű (Kis: 7,02%; Nagy: 8,45%), származási helyre utaló (Kis: 5,26%; Nagy: 4,23%), illetőleg külső vagy belső tulajdonságra utaló (Kis: 2,63%; Nagy: 2,82%) családnevek mellett. Szabó T. Attila végső konklúziójában maga is arra a megállapításra jutott, hogy a nemzedékviszonyító elemek leggyakrabban apa- (ahogy Szabó T. fogalmaz: keresztnév), illetőleg foglalkozásnévi eredetű családnevek előtt a leggyakoribbak (Szabó T. 1967, 64. p.).
Hangsúlyozni kell azonban: önmagában az a tény, hogy ezeknek a több tagból álló családneveknek a följegyzését az 1720-as összeírásban szinte kivétel nélkül két külön szóba írva találjuk, nem számít döntő érvnek sem amellett, hogy ragadványnévszerűek, sem amellett, hogy valódi, többes tagolódású családnevek lennének. Különösen annak fényében nem, hogy egységes helyesírási elvek híján szinte minden összetétellel keletkezett helynevet is több külön szóba írva hagytak rá az utókorra az összeíró ívek (pl. Arok Szállás, Göncz Ruszka, Kis Baráthy, Rácz Fejerto, Szent Márton Káta, Szölös Ardo, Tisza Nána stb.).
A fenti kitérőt azért tartottam fontosnak beiktatni, mert ezzel is hangsúlyozni szerettem volna, hogy a Nagy családnév esetében milyen jelentős szerepet tulajdoníthatunk a nemzedékviszonyító elemet tartalmazó jelzős szerkezetek redukciójának. Vélhetően sokkal nagyobbat, mint ahogy azt a laikus nyelvérzék gondolná. Mindezt annak ellenére állíthatjuk, hogy a korpusz alapján olyasféle korrelációs párokat alig-alig tudnánk fölsorakoztatni, amilyeneket Szabó T. Attila a levéltári forrásokra támaszkodva gyűjtött csokorba a történeti névállományból (Szabó T. 1967), hiszen a legtöbb esetben egy-egy háztartásból csupán egyetlen személy nevét jegyezték föl: a családfőjéét. Azt pedig az összeíró íveken nem rögzítették, hogy voltak-e családi kötelékek a Joannes Kis Pál-ok és Joannes Nagy Pál-ok között.
A dolog természetéből adódik, hogy az alábbiakban a lexikai típus alá csak a puszta Nagy-okat és annak változatait soroltam be. A történeti rétegben négy írásképváltozattal számoltam: Nagy (2353 adat), Nagj (303 adat), Nagi (61 adat), Nágy (4 adat). Közülük csupán kettő maradt meg a napjainkig eltelt közel három évszázad során: a Nagy és a Nadj. Az első nem igényel különösebb ortográfiai magyarázatot, a második viszont igen. A j ugyanis többes (hang)értéket takar: egyaránt jelölhette az i-t, a j-t és az y-t. Ez a nyugat-európai nyelvekben sem ritka jelenség. A magán- és mássalhangzóérték szétválása nagyjából a 16–17. században következik be (vö. Korompay 2004, 282. p.). Talán korántsem véletlen, hogy a 18. század eleji forrásunkban az adatok döntő többségét a [gy] hangértékű g + y-os betűkettőzéssel leljük meg, és csak töredékét a régebbi korok archaikus írásmódját továbbvivő j-s, illetőleg i-s formában. A 2009-es korpuszban tehát ugyancsak helyesírási kövületnek kell tekintenünk a hatvan Nadj alakban kimutatható adatunkat. Ezzel szemben a hatvannyolc Nad egyfajta neologizmusnak minősítendő. Egyértelműen a 20. században politikai határokkal leválasztott magyar népességgel hozható összefüggésbe. Éspedig oly módon, hogy a környező nyelvekben a jellegzetesen magyar névállományt a hatóságok államnyelvűsítették. Ennek során egyes hangok betűjelét mellékjeles formákkal váltották fel. Így lett a Kiss-ből Kiš ~ Kišš [kis], a Nagy-ból pedig Naď [nagy] stb. (vö. Lanstyák 1991, 18–19. p.; 2000, 172. p.; Vörös 2004, 48., 237., 249–254. p.; 2011, 282–286. p.). A 20–21. század során a magyar hatóságokkal jogviszonyba kerülő határon túli magyarok nevéről a magyar okmányokban óhatatlanul elmarad a palatalizációra utaló mellékjel. Az eredeti magyar név alkatát tehát önkényesen helyreállítani nem lehet, ugyanakkor az államnyelvűsített forma is sérül. Az ilyen nevekről akár azt is mondhatnánk, hogy a többszörös torzulás következtében nyelvi senki földjére kerültek. Magyarázatra szorulna a történeti anyagban a Nágy. Ennek kapcsán eredendően arra gyanakodtam, hogy az illabiális ™ hangot akarták vele visszaadni. Ám az ide tartozó négy adat nyelvföldrajzi vizsgálata azzal szembesített, hogy egyik név sem hozható közvetlen kapcsolatba a palóc nyelvjárásterülettel: egy-egy ugyanis a Hajdú megyei Nánáson (ma: Hajdúnánás) és a Nyitra megyei Farkasdon (ma: Vágfarkasd, szlk. Vlčany), kettő pedig Buda szabad királyi városában bukkant fel.
Mielőtt a Nagy lexikai típusa téri tagozódásának tárgyalására térnénk, érdemes egy pillantást vetni a szóban forgó családnév történeti rétegen és a 2009-es korpuszon belüli részesedésére. Annyit elöljáróban előre kell bocsátanunk, hogy két, egymástól sok tekintetben lényegesen különböző összetételű korpusszal van dolgunk. Az első esetben alapvetően a 18. század eleji Magyar Királyság durván hárommilliósra becsült népessége mintegy 6%-ának a névállománya áll rendelkezésünkre (vö. Acsády 1896, Dávid 1957). Ezen túl lényeges különbségként említhetjük a következőket: 1. csak az adóköteles felnőtt népesség nevei állnak rendelkezésünkre, ám azok is döntően férfineveket takarnak; 2. eleve nem a születési nevekkel van dolgunk, hiszen a névállomány egy része mozgásban van; 3. a korpusz nem tekinthető egységes nyilvántartási elvekre épülő forrásnak, hiszen a conscriptorok a nyelvi adatokat is az adatközlők bemondására hagyatkozva jegyezték föl (lásd föntebb a 2. és 4.1. fejezetben az élőnyelvi minősítéssel kapcsolatban elmondottakat); 4. a nevek rögzítése a korabeli helyesírási gyakorlat sokszínűségét tükrözi; 5. a korabeli Magyar Királyság határai lényegesen nagyobb régiót fedtek le a magyar nyelvterületből, mint amire a Trianonban, illetőleg az 1947-es párizsi békeszerződés során kialakított határokon belül ráláthatunk. Ezzel szemben a 2009-es adatbázis: 1. a teljes magyarországi lakónépesség családneveit tartalmazza; 2. benne születési neveket vizsgálhatunk (kivételnek számítana ez alól azok a hivatalos névváltoztatások, amelyek a születési neveket érintik), vagyis asszonyneveket és házassági neveket nem tartalmaz; 3. minden korosztály és mindkét nem nevei fellelhetők benne; 4. az állami adminisztráció által megszabott követelmények szerinti ortográfiai gyakorlat áll az adatok rögzítésének hátterében; 5. nagyfokú állandósággal és megállapodottsággal jellemezhető.
A fentiekből is látható, hogy a két korpusz mind mennyiségi, mind pedig minőségi tényezők tekintetében jelentős eltéréseket mutat. Éppen ezért szükséges kellő óvatossággal eljárni, amikor a két időszelet névföldrajzi eredményeinek egybevetése során állításokat fogalmazunk meg. Az elmondottak ellenére úgy gondolom, nem mondhatunk le arról, hogy a névföldrajzi térképlapokat összevessük.
Mielőtt ezt megtennénk, a Nagy családnév lexikai típusának az összkorpuszokon belüli részesedését is szükségesnek látszik érinteni. Az 1720-as összeírás 2 729 adata az adatbázis egészéhez képest 1,53%-ban részesedik. Így a korban a harmadik leggyakoribb családnévnek számított. Ezzel szemben a 2009-es korpuszban a szóban forgó családnévnek 237 501 adatát sikerült kimutatni. Tehát a teljes lakónépességnek 2,33%-a viselte ezt a nevet. Ez a különbség mintha arra utalna, hogy a közel háromszáz év alatt jelentősen nőtt az össznépességen belül a Nagy családnevűek részesedése. Ez azonban egyéb támpontok híján csak feltevés, hiszen az 1720-as korpusz alapján még hozzávetőlegesen sem tudjuk meghatározni, hogy a háztartásokat valamiféleképpen reprezentáló adóköteles személyek mögött mekkora a látencia. Továbbá azt sem tudjuk, hogy az adómentességet élvezők között ténylegesen hány személy viselhette a Nagy családnevet. A százalékos részesedés növekményéhez természetesen több tényező is hozzájárulhatott: részben a Nagy családnevű családok átlagosnál nagyobb szaporasága, valamint az, hogy az átlagosnál több fiú, mint leány vitte tovább a nevet a családban. Ezen túl természetesen hozzájárulhatott a növekményhez az is, hogy a 19. század elejéig tulajdonképpen a névváltozás és/vagy névváltoztatás nem volt engedélyhez kötve. Az említett tényezők alakulásáról azonban a köztes időszakokban vajmi keveset tudunk. Támpontul csupán az engedélyköteles névváltoztatások állnak rendelkezésünkre, noha ezek sem minden időszakból és korántsem teljes körűen. Ahol mégis némi fogódzót találhatnánk, ott a személyiségi jogok védelmére hivatkozva éppen nyelvi adatok közlésének hiányába ütközünk (lásd pl. Farkas 2009). Éppen ezért kénytelenek vagyunk Szentiványi Zoltán Századunk névváltoztatásai c. munkájára hagyatkozni (Szentiványi 1895). Ebből a munkából kigyűjtöttem az összes olyan esetet, amikor a névváltoztató elhagyta vagy éppen ellenkezőleg: felvette a Nagy családnevet. Mindösszesen négy olyan tétel adódott, amikor a Nagy-ot cserélték másra: Balázs-ra, Gömörei-re, Koós-ra és Kovács-ra (lásd Szentiványi 1895, 31., 89., 132., 136. p.). A további példák is azt mutatják, hogy ebben a korban a névváltoztatás egyértelműen a névmagyarosítást takarta. Százkét olyan esetet számoltam össze, amikor a korabeli hatóságok a kérvényező(k)nek a Nagy családnév felvételét engedélyezték (lásd Szentiványi 1895, 165–167. p.). Ebben a körben mindössze három kérvényező kívánta magyar eredetű nevét elhagyni (Bab, Gombás, Mányai). Tíz család szláv nyelvi alkatú nevet akart magyarosítani. A többség viszont egyértelműen német eredetű nevétől akart szabadulni. Közülük is legtöbben a Gross-tól és a Grossmann-tól váltak meg. Láthatjuk, hogy Szentiványi nagyságrendileg tizenötezres adattárához képest viszonylag jelentéktelen azoknak az eseteknek a száma, amelyek alapján arra a következtetésre juthatnánk, hogy a névváltoztatás jelentősen hozzájárult volna a Nagy családnév földuzzadásához.9 Amint fentebb már jeleztem, a 20. században a hatóságok az olyan nevek felvételének engedélyezését (is) kerülték, amelyek feltűnően gyakoriak voltak (a két világháború közötti normatív névjegyzékről lásd Farkas 2009, 53. p.).
A fentiek összegzéseként megállapíthatjuk, hogy közvetlen források nem állnak rendelkezésünkre annak közelebbi körülhatárolására, milyen extralingvális okokra vezethető vissza a két időszelet viszonylatában a Nagy százalékos részesedésének növekedése. Annyi bizonyosnak tűnik, hogy a 19–20. századi névváltoztatások nem játszottak jelentős szerepet ebben a változásban.
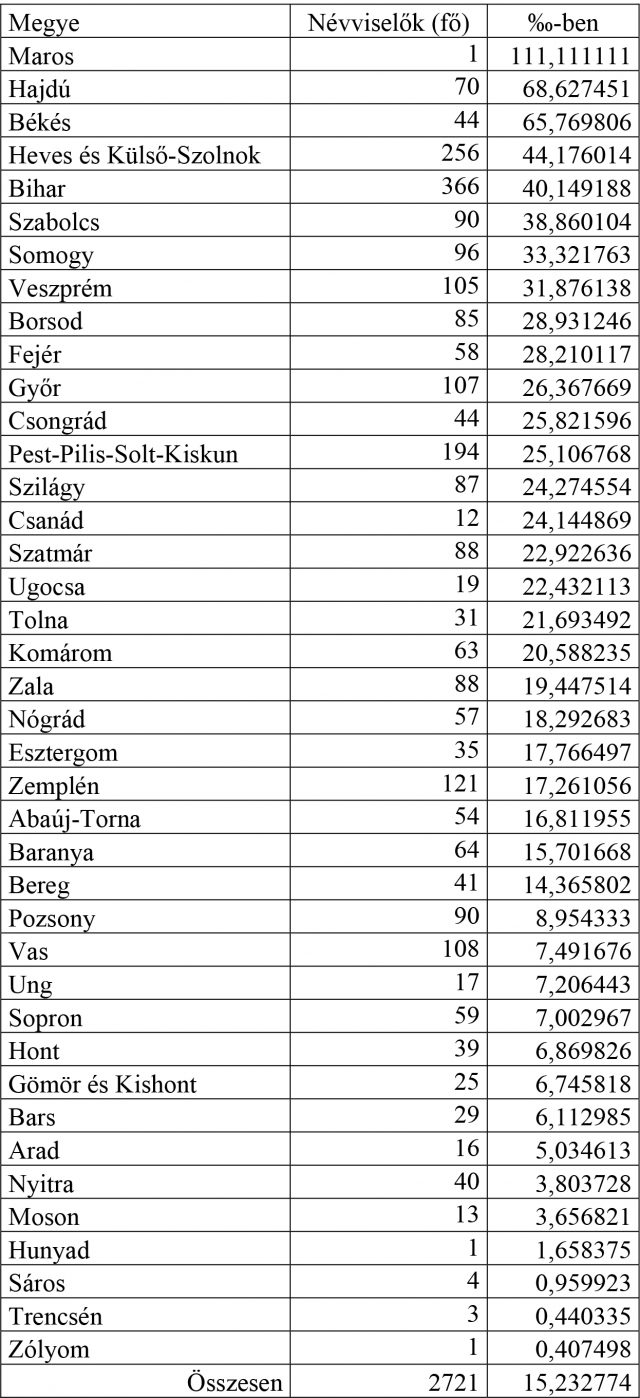
A továbbiakban a szóban forgó családnév nyelvföldrajzi tagozódását fogjuk vallatóra. Ehhez az 1720-as korpuszból elsőként az adatok megyék szerinti eloszlását mutatom be táblázatos formában.
A táblázatból azonnal kitűnik, hogy az ország keleti régiójában sokkal gyakoribb a név, mint a Duna folyásától nyugatra. Némileg megtévesztő a lista élén álló Maros megyei adat kiugróan magas ezrelékes értéke, ám ezt azzal magyarázhatjuk, hogy ebből a térségből mindössze kilenc névadathoz kellett viszonyítani az ott felbukkanó egyetlen adatot. A nagyobb lélekszámú megyék közül mindenekelőtt Hajdú és Békés megye tűnik ki a maga közel hét százalékával. A gyakorisági lista végén található 18 utolsó megye adata mintegy előrevetíti, hogy a peremvidékeken kevésbé fognak elszíneződni a kartogramok, mint a kompakt magyar nyelvterületnek számító központi régiókban. Ez nyilván azzal magyarázható, hogy a Szabó-hoz hasonlóan itt is egyértelműen magyar névképzéssel van dolgunk.
2. táblázat. A Nagy gyakorisága az 1720-as korpuszban
A történeti adatok téri tagozódását bemutató térképek alaposabb tanulmányozása arról győz meg bennünket, hogy a név a korabeli magyar nyelvterületnek lényegileg minden régiójában adatolható, igaz, egyes peremterületeken – így délen is – meglehetősen szórványosan. A településenkénti bontású térképről az is leolvasható, hogy egybefüggőbb foltok inkább csak a nyelvterület keleti részén alakulnak ki. A Dunántúlon, különösen a Balatontól délre eső tájakon sok foghíjjal találkozni. Itt sem kerülheti el a figyelmünket, hogy a Duna–Tisza közének középső és déli részén, Békés, Csongrád és Csanád megye területén jelentkező hiátusok minden bizonnyal a török pusztítással hozhatók összefüggésbe.
15. ábra. A Nagy családnév földrajzi elterjedtsége (1720) (Az 1910-es közigazgatási beosztásra vetítve)
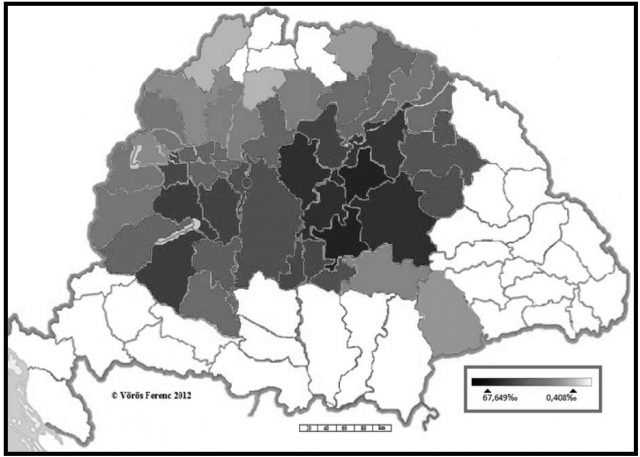
16. ábra. A Nagy családnév földrajzi elterjedtsége (1720) (A 2011-es közigazgatási beosztásra vetítve)
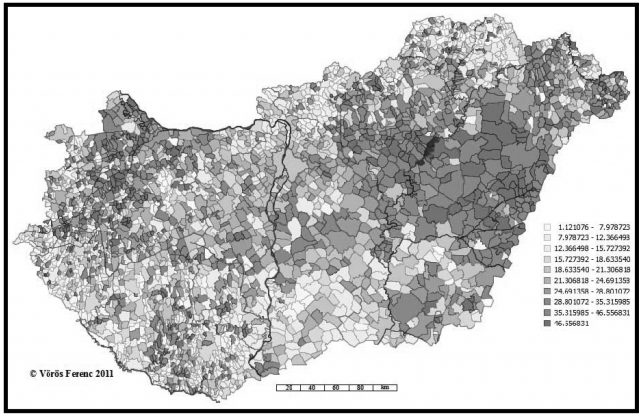
17. ábra. A Nagy családnév földrajzi elterjedtsége megyénként (2009) (A 2011-es közigazgatási beosztásra vetítve)
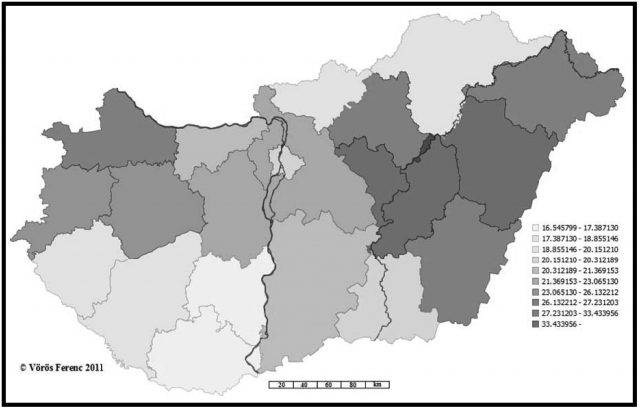
18. ábra. A Nagy családnév földrajzi elterjedtsége településenként (2009) (A 2011-es közigazgatási beosztásra vetítve)
Az elmondottak alapján – mindent egybevetve – kevésbé látom meggyőzőnek a Fodor–Láncz szerzőpárosnak azt az állítását, miszerint a Nagy esetében az „alföldi névhasználat jellemző sajátossága” lenne a Nagy használata (N. Fodor–F. Láncz 2011, 183. p.). Azt pedig végképp problémás megállapításnak gondolom, hogy a szerzőpáros az idézett helyen a Nagy-ról csupán mint jellegzetes tulajdonságjelölő névről beszél, egyáltalán nem számolván egyéb, fentebb számba vett motivációival. Ezt látszanak cáfolni Szabó T. Attila fentebb idézett történeti adatai az erdélyi régiségből (Szabó T. 1967).
A jelenkori adatok kartogramjaihoz nem mellékelem a megyénkénti bontású adatokat. Ezt pótlandó egy korábbi munkámhoz irányítom az olvasót (Vörös 2010, 26. p.). A szinkrón adatok alapján előállított térképek ugyancsak azt látszanak igazolni, hogy lényegileg két góccal kell számolnunk: az egyik a már említett Tisza melléki, a másik az északnyugat-dunántúli térség. Ha figyelembe vesszük, hogy a 17. ábrán intervallumskálát nem alkalmaztam, vagyis az egyes településeket szimbolizáló poligonok mindegyike azonos telítettségű színekkel lett kitöltve, akkor nem kerülheti el a figyelmünket a 16. és a 18. ábra nagyfokú hasonlósága. Megjegyzem, a történeti adatok megyénkénti bontású térképe is többé-kevésbé összhangban van egymással, noha a két időszelet között majd háromszáz évnyi a távolság. A különbségek nyilván azoknak a tényezőknek az összességéből adódhatnak, amelyeket fentebb öt-öt pontba szedve vettem számba.
Polémiára ad okot a Fodor–Láncz szerzőpárosnak az az állítása is, amelyben még ha óvatosan is, de kijelentik, hogy a Nagy családnév elterjedtsége „feltehetőleg nincs összefüggésben a többi nagy megterheltségű név […] földrajzi sajátosságaival” (N. Fodor– F. Láncz 2011, 183. p.). Nem könnyű vitába szállni a fentebb idézett gondolattal, ha csupán a példálózásukban szereplő Kovács, Tót, Varga kartogramjait ismerjük. Jóllehet ebben a munkában nem áll szándékomban az összes gyakoribb családnév tárgyalása, azért az eddig elkészült térképek alapján kellő biztonsággal állítható, hogy akadnak olyan családnevek a gyakori listák élén, amelyek lényegileg a nyelvterület nyugati térségében töltik ki azokat a kisebb-nagyobb hiátusokat, amelyek a Nagy történeti és jelenkori kartogramjain figyelhetők meg. Ezek között említhetjük többek között a Horvát-ot.
Végezetül két dologra szeretném ismételten ráirányítani a figyelmet. Az egyik, hogy a (vár)megyénkénti bontásban kartografált adatok gyakorta megtévesztik a szemet, ha csak ezekre hagyatkozunk. Igaz ez természetesen akkor is, ha csupán településenkénti bontásban vizsgálódunk. A leginkább célravezető módszer az, ha a két térképtípust egymás mellé téve analizáljuk. A másik, hogy az 1715-ös összeírás adatbázisa alapján többek között a legtöbb nevet tartalmazó Vas megyére nincs rálátásunk. Csak emlékeztetőül idézem, hogy innen 14 416 adózó nevét hagyták ránk az összeíró ívek. Nyitra (10 516 fő), Pozsony (10 052 fő), Bihar (9 120 fő) és Sopron (8 425 fő) megyét leszámítva valamennyi közigazgatási egység személynevei jócskán tízezer alatt maradnak. Az országos átlag alig több mint 3 600. A pozsareváci béke után Magyar Királysághoz csatolt Temesközből az átlagnál is kevesebb adattal számolhatunk. Nyilvánvaló, hogy amikor az 1715-ös és az 1720-as adatbázisok alapján akarunk nyelvföldrajzi következtetéseket levonni, ezekre az eltérésekre is minden esetben figyelemmel kell lenni, még ha nem tűnnek is jelentős különbségeknek.
4. Összegzésként megállapíthatjuk, hogy a névföldrajz számos olyan fehér folt kitöltésében kínál segítséget a kutatók számára, amelyekre eddig nem tudtunk magyarázattal szolgálni. A korábbinál nagyobb, a nyelvterület egészét vagy jelentős részét lefedő adatbázisok térképre vetített adatai nemcsak a nyelvészek, hanem az érintkező szakterületek számára is érdekesek lehetnek. Ehhez azonban minden oldal részéről az eddigieknél szorosabb együttműködésre lenne szükség.
Irodalom
Acsády Ignác 1896. Magyarország népessége a Pragmatica Sanctio korában. Budapest, Országos Magyar Királyi Statisztikai Hivatal.
Alexics György 1914. Oláh. Román. Magyar Nyelvőr, 43. évf. 401–408. p.
Asbóth Oszkár 1900. Blagoje Brančić: Madjarska Gramatika. Magyar Nyelvőr, 29. évf. 323–329. p.
Bárczi Géza 1967. A magyar szókincsre vonatkozó etimológiai kutatások jelenlegi állása. Magyar Nyelv, 63. évf. 285–292. p.
Bíró Boglárka 2006. Bevezetés a cigányság néprajzába. In (Forrai R. Katalin szerk.): Ismeretek a romológiai alapképzési szakhoz. Pécs, PTE BTK NTI Romológiai és Nevelésszociológia Tanszék, 58–74. p.
Brechenmacher, Karlmann 1957–1963. Etymologisches Wörterbuch der deutschen Familiennamen I–II. Limburg a. d. Lahn, C. A. Starke Verlag.
Dávid Zoltán 1957. Az 1715–20. évi összeírás. In (Kovacsics József szerk.): A történeti statisztika forrásai. Budapest, Közgazdasági és Jogi Kiadó, 145–199. p.
EWUng = Benkő Loránd (főszerk.) 1993–1995. Etymologisches Wörterbuch des Ungarischen 1–2. Budapest, Akadémiai Kiadó. 1993–1995. – 3. Register. 1997.
Farkas Tamás 2009. Családnév-változtatás Magyarországon. Budapest, Akadémiai Kiadó.
Fehértói Katalin 1969. A XIV. századi magyar megkülönböztető nevek. (Nyelvtudományi Értekezések 68.) Budapest, Akadémiai Kiadó.
N. Fodor János–F. Láncz Éva 2011. A Történeti magyar családnévatlasz előmunkálatairól. Névtani Értesítő, 33. évf. 175–190. p.
Hajdú Mihály 1990. Adalék a XVI. századi magyar nyelvjárások hangrendszeréhez. Magyar Nyelv, 86. évf. 77–80. p.
Hajdú Mihály 1994. A középmagyar kor személynévtörténete (1526–1772). I–III. Budapest. (Kéziratban az MTA Könyvtárában)
Hajdú Mihály 2003. Általános és magyar névtan. Budapest, Osiris Kiadó.
Hajdú Mihály 2010. Családnevek enciklopédiája. Budapest, Tinta Könyvkiadó.
Hefty Gyula Andor 1911. A térszíni formák nevei a magyar népnyelvben. Magyar Nyelvőr, 40. évf. 155–169. p.
Horger Antal 1910. Egy ismeretlen magyar hangtörvény IV. Magyar Nyelvőr, 39. évf. 337–343. p.
Ionescu, Cristian 2004. Dicţionar de onomastică. Bucureşti, Editura Elion.
Iordan, Iorgu 1983. Dicţionar al numelor de familie româneşti. Bucureşti, Editura Ştiinţifică şi Enciclopedică.
Juhász Dezső 1984. A magyar tájnevekről. Magyar Nyelvőr, 108. évf. 232–236. p.
Juhász Dezső 2001. A nyelvjárási régiók. In (Kiss Jenő szerk.): Magyar dialektológia. Budapest, Osiris Kiadó, 261–324. p.
Kázmér Miklós 1970. A »falu« a magyar helynevekben. XIII–XIX. század. Budapest, Akadémiai Kiadó.
Kázmér Miklós 1970. XIV–XVIII. századi tulajdonnevek nyelvtörténeti értékesítése (A -si képző kialakulása). In (Kázmér Miklós–Végh József szerk.): Névtudományi előadások. II. Névtudományi Konferencia. (Nyelvtudományi Értekezések 70.) Budapest, Akadémiai Kiadó, 60–69. p.
Kázmér Miklós 1993. Régi magyar családnevek szótára XIV–XVII. század. Budapest, Magyar Nyelvtudományi Társaság.
Kemény István 1997. A magyarországi cigányság helyzete. In (Vajda Imre szerk.): Periférián – Roma szociológiai tanulmányok. Budapest, Ariadne Kulturális Alapítvány, 644–655. p.
Kemény István–Janky Béla–Lengyel Gabriella 2004. A magyarországi cigányság 1971–2003. Budapest, Gondolat–MTA Etnikai-nemzeti Kisebbségkutató Intézet.
Kiss Lajos 1996. A Kárpát-medence régi helynevei. Magyar Nyelvőr, 120. évf. 440–450. p.
Kniezsa István 1965/2003. A magyar és a szlovák családnevek rendszere. In uő: Helynév- és családnévvizsgálatok. Kiss Lajos bevezető tanulmányával. Budapest, Lucidus Kiadó.
Korompay Klára 2004. Az ómagyar kor helyesírás-története. In (Kiss Jenő–Pusztai Ferenc szerk.): Magyar nyelvtörténet. Budapest, Osiris Kiadó, 101–105., 281–300., 579–595., 697–709., 781–788. p.
Korompay Klára 2004. Helyesírás-történet. In (Kiss Jenő–Pusztai Ferenc szerk.): Magyar nyelvtörténet. Budapest, Osiris Kiadó. 101–105., 281–300., 579–595., 697–709., 781–788. p.
Korompay Klára 2010. Mit nyújthat a helyesírás-történet a szinkrón magyar családnévatlasz munkálataihoz? In (Vörös Ferenc szerk.): A nyelvföldrajztól a névföldrajzig (I.) (MNyTK 234.) Szombathely–Budapest, Savaria University Press–Magyar Nyelvtudományi Társaság, 60–70. p.
Kúnos Ignácz 1885. A helynevekben levő népetymologiáról. Magyar Nyelvőr, 14. évf. 97–102. p.
Lakatos Szilvia 2006. A romani/lovári nyelv. In (Forrai R. Katalin szerk.): Ismeretek a romológiai alapképzési szakhoz. Pécs, PTE BTK NTI Romológiai és Nevelésszociológia Tanszék, 111–129. p.
Lanstyák István 1991. A szlovák nyelv árnyékában. In (Kontra Miklós szerk.): Tanulmányok a határainkon túli kétnyelvűségről. Budapest, Magyarságkutató Intézet, 11–71. p.
Lanstyák István 2000. A magyar nyelv Szlovákiában. Budapest–Pozsony, Osiris Kiadó, Kalligram Kiadó, MTA Kisebbségkutató Műhely.
Laziczius Gyula 1941. Egy nagy pör felújítása. Nyelvtudományi Közlemények, 51. évf. 241–279. p.
MCsNA 2009. Magyar családnévatlasz. Kutatásvezető: Vörös Ferenc.
MCsTt 2011. Magyar családnevek térképtára. Elektronikusan tárolt adatbázis. Kutatásvezető: Vörös Ferenc.
MMCsA 2009. Mai magyar családnevek adatbázisa (Database of Hungarian Surnames). Elektronikusan tárolt adatbázis. Kutatásvezető: Vörös Ferenc.
Moór Elemér 1949. A magyar nyelvtörténet őstörténeti vonatkozásai. Magyar Nyelvőr, 73. évf. 20–22. p.
Moór Elemér 1954. A magyar lótenyésztési és lovasterminológia szláv elemei szó-, nép- és művelődéstörténeti szempontból. Magyar Nyelv, 50. évf. 67–76. p.
OrszÖsszír. 1720/2012. Az 1720. évi országos összeírás. Elektronikusan tárolt adatbázis. Kutatásvezető: Vörös Ferenc.
Ördög Ferenc 1998. Zala megye népességösszeírásai és egyházlátogatási jegyzőkönyvei (1745–1771). Budapest–Zalaegerszeg, Magyar Tudományos Akadémia Nyelvtudományi Intézete–Zala megye Önkormányzati Közgyűlése.
Ördög Ferenc 2008. XVIII. századi családnevek írásmódjának helyesírástörténeti rétegei. In uő: Válogatott tanulmányok. Nagykanizsa, Czupi Kiadó, 279–282. p.
Pais Dezső 1912. Göcsej. Magyar Nyelv, 8. évf. 124–126. p.
Penavin Olga 1958. Kórógy lakosságának névanyag. Magyar Nyelvőr, 82. évf. 476–481. p.
Rubinyi Mózes 1901. Adalékok a moldvai csángók nyelvjárásához V. Szókincs. Magyar Nyelvőr, 30. évf. 170–182. p.
Simonyi Zsigmond 1906. A nyíl és a nyír. Magyar Nyelvőr, 35. évf. 393–401. p.
Szabó T. Attila 1943. Az elve vízneveinkben. Magyar Nyelv, 39. évf. 73. p.
Szabó T. Attila 1967. Az erdélyi régiség személynévanyagának nemzedékviszonyító elemei. Magyar Nyelv, 63. évf. 51–64. p.
[Szentiványi Zoltán] 1895. Századunk névváltoztatásai. Helytartósági és miniszteri engedélylyel megváltoztatott nevek gyűjteménye 1800–1893. Eredeti okmányok alapján összeállította a Magyar Heraldikai és Genealógiai Társaság egyik igazgató-választmányi tagja. Budapest, Hornyánszky Viktor kiadása.
Tagányi Károly 1913. Gyepü és gyepüelve II. Magyar Nyelv, 9. évf. 145–152. p.
TESz = Benkő Loránd (főszerk.) 1967–1976. A magyar nyelv történeti-etimológiai szótára 1–3. Budapest, Akadémiai, 1967–1976. – 4. Mutató. 1984.
Vörös Ferenc 2004. Családnévkutatások Szlovákiában. Pozsony, Kalligram Kiadó.
Vörös Ferenc 2009. Széljegyzetek a magyar családnévatlasz előmunkálatai közben. Névtani Értesítő, 31. évf. 185–197. p.
Vörös Ferenc 2010. Családnevek térképlapjainak nyelvföldrajzi vallomása. (MNyTK 235.) Budapest, Magyar Nyelvtudományi Társaság.
Vörös Ferenc 2011. Nyelvek és kultúrák vonzásában. I. Személynevek a magyar nyelvterület északi pereméről. Pozsony, Kalligram Kiadó.
Vörös Ferenc 2013. Mutatvány az 1720-as országos összeírás névföldrajzából. Szombathely, Savaria University Press.
Zoltán András 2004. A magyar nyelv régi szláv jövevényszavai és a szláv nyelvtörténet. Kisebbségkutatás, 13/4. évf. 671–674. p.
Források
Az 1715-ös összeírás (Jelzete: N 78) (Filmtári helye: 3119–3131. dobozok)
Az 1720-as összeírás (Jelzete: N 79) (Filmtári helye: 3131–3149., 3154. dobozok)
ConsReg 1715 = Conscriptio Regnicolaris 1715. N 78. MOL., 3119–3331. doboz. Digitalizált kiadás. Szerk. H. Németh István. Az 1715. évi országos összeírás. (DVD-ROM) Budapest. Digitalizált változat online elérhetősége: http://193.224.149.8/adatbazisokol/adatbazis/2 (Utolsó letöltés: 2012. 12. 29.)
ConsReg 1720 = Conscriptio Regnicolaris 1720. N79. MOL., 3131–3149, 3154. doboz. Digitalizált változat online elérhetősége: http://193.224.149.8/adatbazisokol/adatbazis/52 (Utolsó letöltés: 2012. 12. 29.)